DeepSeek MoE 推理是如何“边算边发”的:从 DeepEP 到 Profile Data 的拆解
摘要
MoE 推理系统里最难建模的部分,往往不是拓扑本身,而是计算与通信的真实组织方式。
同样是 expert parallelism,Prefill 更像高吞吐、大批量、长计算核与长尾通信的重叠问题;Decode 则更像低时延、小步长、高频短通信的尾延迟问题。两者虽然都属于推理阶段,但在时间线上几乎表现为两种不同系统。
本文基于 DeepSeek 开源的 DeepEP、profile-data 中的 PyTorch Profiler 轨迹以及 shallowsim 中的性能分析脚本,重新梳理 DeepSeek-V3 / R1 架构家族在 MoE 推理中的关键行为特征。文章重点关注三个问题:
- DeepEP 到底解决了什么问题
- Prefill 和 Decode 的计算-通信模式为何截然不同
- 这些真实数据对后续仿真建模意味着什么
如果你关心的是 MoE 推理中的 all-to-all、双 micro-batch 重叠、SM 占用方式,或者希望在仿真器里更接近真实系统行为,这篇文章可以作为一份系统性的背景材料。
引言
在做 MoE 推理系统建模时,最难的部分往往不是“网络拓扑怎么连”,而是“真实系统到底在什么时候算、什么时候发、算和发到底重叠到什么程度”。
这一点在 DeepSeek 的推理场景里尤其明显:同样是 EP 通信,Prefill 和 Decode 的行为完全不像同一种工作负载。
为了避免只保留结论、丢掉原始上下文,本文保留了原始分析中的表格、配图和关键统计,并在此基础上做结构重组,让它更适合博客式阅读。
相关项目与资料:
- DeepEP: https://github.com/deepseek-ai/DeepEP
- Profile-Data: https://github.com/deepseek-ai/profile-data/tree/main
- DeepSeek-V3: https://github.com/deepseek-ai/DeepSeek-V3
- DualPipe: https://github.com/deepseek-ai/dualpipe
- shallowsim: https://github.com/zartbot/shallowsim
工程概述
DeepEP库
DeepEP 是 DeepSeek 开源的 MoE / EP 通信库,重点面向专家并行中的 all-to-all 通信,也就是常说的:
1 | **Dispatch**: Efficiently distribute tokens to corresponding expert nodes |
如果只看一句话,它的价值可以概括为:
它不是在抽象地讨论 EP,而是在真实 GPU、真实 NVLink、真实 RDMA 环境里,把 MoE dispatch / combine 做成了高吞吐和低时延两套内核。
测试环境与限定条件
| 类别 | 内容 |
|---|---|
| GPU | NVIDIA H800 |
| NVLink | 节点内互联,理论上限约 160 GB/s |
| RDMA 网卡 | NVIDIA ConnectX‑7(CX7)InfiniBand 400 Gb/s,约 50 GB/s 最大带宽 |
| 普通内核测试设置 | 4096 tokens/batch,hidden=7168,top‑4 groups,top‑8 experts,FP8 dispatch,BF16 combine |
| 低时延内核测试设置 | 128 tokens/batch,hidden=7168,top‑8 experts,FP8 dispatch,BF16 combine |
| 必备软件/硬件 | Ampere SM80 或 Hopper SM90(或支持 SM90 PTX ISA 的架构);PyTorch ≥ 2.1;CUDA:SM80→≥11.0,SM90→≥12.3;NVLink(节点内);RDMA 网络(节点间);NVSHMEM 依赖 |
| 限定/说明 | 低时延内核为纯 RDMA;普通内核含 NVLink→RDMA 异构域前传;实现与 DeepSeek‑V3 论文存在轻微差异 |
| 参考来源 | DeepEP README.md |
普通内核性能(NVLink + RDMA 前传)
这类内核更偏高吞吐,更适合训练和推理 Prefill。
| 类型 | Dispatch #EP | 瓶颈带宽 | Combine #EP | 瓶颈带宽 |
|---|---|---|---|---|
| Intranode | 8 | 153 GB/s(NVLink) | 8 | 158 GB/s(NVLink) |
| Internode | 16 | 43 GB/s(RDMA) | 16 | 43 GB/s(RDMA) |
| Internode | 32 | 58 GB/s(RDMA) | 32 | 57 GB/s(RDMA) |
| Internode | 64 | 51 GB/s(RDMA) | 64 | 50 GB/s(RDMA) |
低时延内核性能(纯 RDMA)
这类内核更偏低时延,更适合 Decode。
| Dispatch #EP | 延迟 | RDMA 带宽 | Combine #EP | 延迟 | RDMA 带宽 |
|---|---|---|---|---|---|
| 8 | 77 µs | 98 GB/s | 8 | 114 µs | 127 GB/s |
| 16 | 118 µs | 63 GB/s | 16 | 195 µs | 74 GB/s |
| 32 | 155 µs | 48 GB/s | 32 | 273 µs | 53 GB/s |
| 64 | 173 µs | 43 GB/s | 64 | 314 µs | 46 GB/s |
| 128 | 192 µs | 39 GB/s | 128 | 369 µs | 39 GB/s |
| 256 | 194 µs | 39 GB/s | 256 | 360 µs | 40 GB/s |
纯PCIE性能
| 类别 | 内容 |
|---|---|
| 平台 | NVIDIA H20(禁用 NVLink) |
| 通信设计 | 1D 设计,所有通信(含节点内/节点间)均经由 RDMA NIC,避免 PCIe/RDMA 分流复杂度 |
| NIC | 8× CX7,单 GPU 对应单 NIC |
| Token 数 | 4096 |
| Hidden 维度 | 7168 |
| TopK | 8 |
| SM 使用 | 24 |
| 连接/缓冲 | 使用 Bounce Buffer,中间缓冲预注册至 NIC 以优化 RDMA 性能并控制显存占用 |
| 规模上限 | 当前 PCIe 模式支持最多 32 ranks |
| 适用场景 | 无 NVLink 的普通模式(通过开关选择传输路径) |
| 使用开关 | 在普通模式下通过 allow_nvlink_for_normal_mode=False 选择 PCIe 路径(参考 tests/test_normal_without_nvl.py) |
性能结果(单位:GB/s)
| Dispatch EP | Dispatch(FP8) | Combine EP | Combine(BF16) |
|---|---|---|---|
| 8 | 53.01 | 8 | 53.67 |
| 16 | 47.98 | 16 | 49.48 |
Profile-Data
The profiling data was captured using the PyTorch Profiler.
单实例视角:为降低复杂度,很多部署用 TP=1、PP=1、DP=1,仅用 EP 个 rank 作为一个“服务实例”。同一集群上会同时运行多个实例以吃满资源。
- 例子:集群 100 张卡,prefill 以 EP32 起一个实例,则该实例占 32 rank;可并行起 3 个实例共用 96 张卡,余下 4 张给其他小实例或空闲。
GPU:NVIDIA H800(compute capability 9.0,132 SM,显存约 84,943,110,144 B ≈ 79.1 GiB)
prefill:dsv3-600B-tp1-worldsize32-ep32-input4096-output1-bs16384-split1-sm24
Decode:worldsize128-ep128
- 可视化方式:在 Chrome 打开 chrome://tracing(或 Edge 的 edge://tracing)加载 JSON 追踪文件。
这里还需要明确一个非常关键的概念:
prompt = 4K表示单条请求的 prompt 长度16K tokens / GPU表示单个 GPU 在该轮 Prefill 中承载的一批请求的总 token 工作量
也就是说:
1 | 每GPU总token数 |
例如,如果单条请求都是 4K,那么:
1 | 16K tokens / GPU ≈ 4 条 4K prompt 的总量 |
这也是为什么 Prefill 和 Decode 在 profile 里的“批量语义”需要单独理解,而不能简单把它们看成单条请求的长度变化。
数据文件
- **train.json (line 1)**:
训练阶段追踪,展示 DualPipe 下前向/反向 chunk 的重叠(每个 chunk 含 4 个 MoE 层)。与 DeepSeek-V3 预训练一致(EP64、TP1、seq=4K),为简化未包含 PP 通信。
- **train.json (line 1)**:

- prefill.json (line 1):
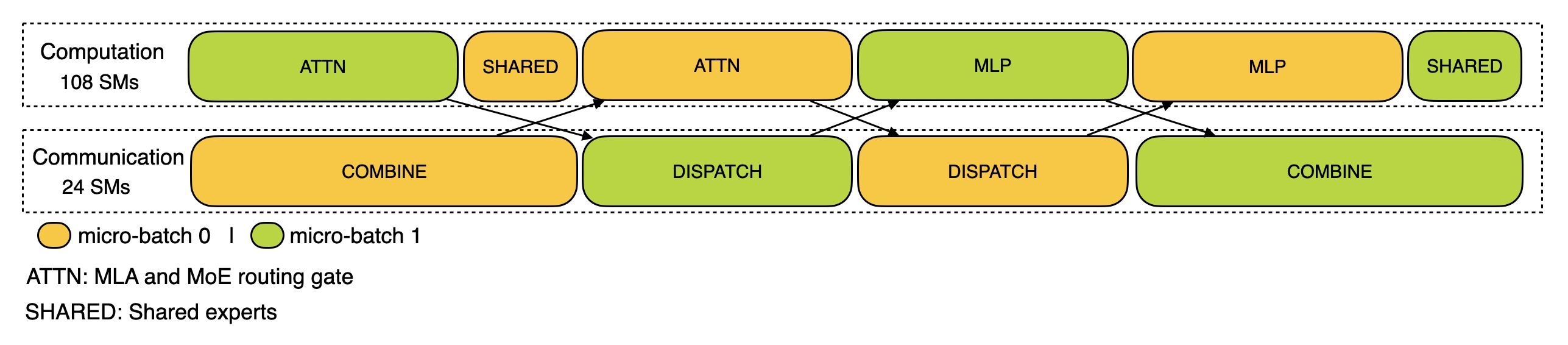
推理-预填充阶段追踪,EP32、TP1、prompt=4K、每 GPU 16K tokens,使用两微批重叠计算与 all-to-all。同一 prompt 可能被分到不同微批。
- decode.json (line 1):
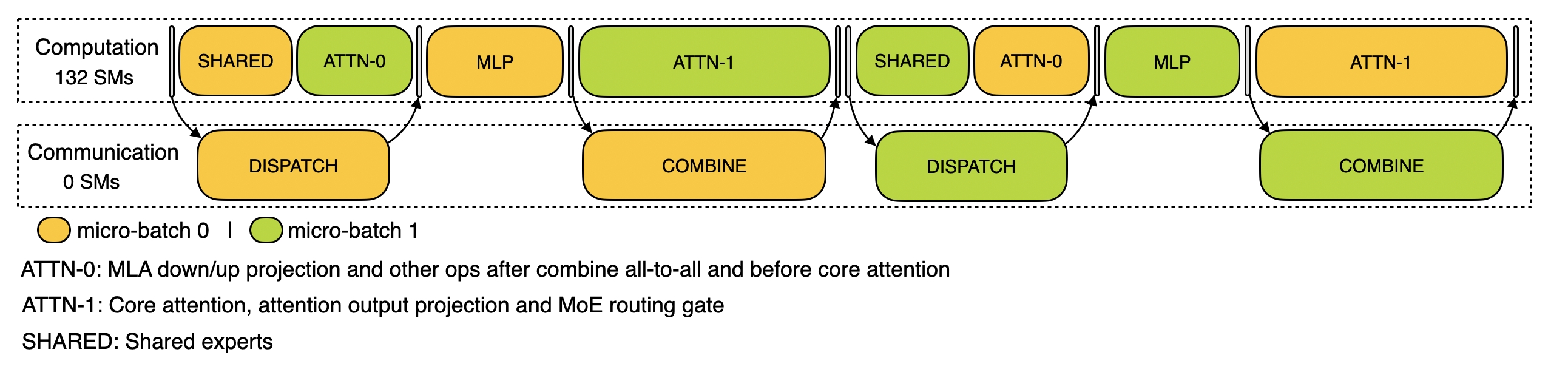
推理-解码阶段追踪,EP128、TP1、prompt=4K、每 GPU 128 请求,同样两微批重叠;解码期 all-to-all 通过 RDMA 发出后不占用 SM,计算结束后等待通信完成。计算与通信并发,计算完成后等待通信结束。
工程分析(Profile-Data)
Prefill 报告
- 总体时窗
- 总时长(trace 窗口,单位近似为微秒):~2,121,463 us(≈ 2.12 s),见 prefill.json (line 1)。
- 计算核持续时间分布(典型)
- p50 ≈ 295 us,p90 ≈ 2.49 ms,p95 ≈ 3.05 ms,p99 ≈ 3.66 ms,max ≈ 4.12 ms。
- 主要类型:FlashAttention/Varlen、GEMM(大矩阵/分组 GEMM/FP8 路径)、LayerNorm/激活等。
- 通信相关内核持续时间分布(DeepEP/All-to-All 路径)
- p50 ≈ 2 us,p90 ≈ 4.54 ms,p95 ≈ 8.17 ms,p99 ≈ 9.36 ms,max ≈ 19.39 ms。
- 典型标识(来自名称,非穷尽):dpsk::ep::internode::dispatch/notify/cached_notify、notify_dispatch 等(见 prefill.json (line 1) 的事件名称聚类)。
- 计算-通信时域关系(重叠度/持续时间)
- 预期行为:两微批交错,GEMM/Attention 计算区间与 all-to-all 通信区间显著重叠;同一 prompt 可能跨微批分割以均衡注意力负载(README.md (line 1))。
- 文本解析结论:存在较多计算核持续在 0.3–4 ms 档,通信出现短促到中等时长的突发(p90 达到毫秒级,尾部可到 10–20 ms),符合“计算-通信交替+重叠”的工作负载特征;由于时钟域标定差异,自动重叠比数值不稳定,建议在 chrome://tracing 中从 GPU tracks 直观核验(在计算核上方能同时看到 DeepEP internode 通信段)。
- 稳定行为规律
- 两微批策略:注意力与 MoE 路由负载被切分到双微批并交错推进,缓解单批尾部等待。
- 通信形态:DeepEP internode dispatch/notify 为主的 all-to-all,呈现“多次短促+少量长尾”的分布,与专家路由/桶化相关。
- 资源占用:计算核以 FlashAttention 与大/分组 GEMM 为主,SM 占用高;通信期间可与计算并发,降低纯通信等待。
Decode 报告
- 总体时窗
- 总时长(trace 窗口,单位近似为微秒):~96,529 us(≈ 96.5 ms),见 decode.json (line 1)。
- 计算核持续时间分布(典型)
- p50 ≈ 13–17 us(不同批次/核混合),p90 ≈ 67–79 us,p95 ≈ 77–241 us,p99 ≈ 155–243 us,max ≈ 0.76–1.60 ms。
- 主要类型:小粒度 Attention/GEMM/Norm/激活等(解码步每次处理 token 较少,单核更短促)。
- 通信相关内核持续时间分布(DeepEP/All-to-All 路径)
- p50 ≈ 17 us,p90 ≈ 67–77 us,p99 ≈ 155 us,max ≈ 1.60 ms(显著短于 prefill 阶段的长尾)。
- 计算-通信时域关系(重叠度/持续时间)
- 预期行为:发起 all-to-all 的 RDMA 后不占用 SM,计算继续进行,尾部对通信有短暂 wait(README.md (line 1))。
- 文本解析结论:计算核短促连续、通信短促多发,呈现高并发/短间隙的节奏;自动重叠比在纯文本聚合下易受时钟域影响,但从核函数时长与类别分布可推断大部分通信与计算重叠,尾端出现轻微同步等待更易在 UI 中被识别。
- 稳定行为规律
- 微批交错:同样采用两微批,但单步计算粒度小,核更短、密度更高。
- 通信占用:通信核更短、更频繁,RDMA 不占 SM,计算流连续性更好,纯通信空洞更小。
- 尾部等待:每步通常在计算完成后等待通信完成,时间远短于 prefill 的长尾通信片段。
两阶段对比与先后规律/频次
- 先后关系
- 单次请求:先执行一次 Prefill(对整个 prompt 进行计算/建缓存),随后进入多轮 Decode(逐 token 生成)。
- 解码循环:每生成 1 个 token 触发 1 次 decode 步(包含计算与 all-to-all 通信)。
- 发生频次
- Prefill:每条请求 1 次。
- Decode:与生成长度线性相关,若生成 N 个 token,则发生 N 次;在长生成任务中,Decode 的累计次数与累计时长通常显著超过 Prefill。
- 行为差异
- Prefill:计算核更长、通信偶有长尾;两微批用于均衡大序列 attention 与 all-to-all,计算-通信交替并重叠,整体受负载均衡和专家路由影响更大。
- Decode:计算核与通信核更短促、更高频;RDMA 不占 SM,重叠更充分,尾部有短等待;单位步延迟受小核调度与同步开销影响更敏感。
参数规律(具体分布见 CSV)
- Prefill
- 计算(Attention/GEMM):0.3–4.0ms(主),max 4.2ms
- 通信(DeepEP A2A 单轮):0.002–9.4ms(主),max 19ms
- 单微批总发量 / 每 GPU:~115MB;对等 ~3.6MB/peer/轮(EP=32)
- 重配置预算:0.2–1.0ms(建议 0.5ms)
- Decode
- 计算:13–240us(主),偶发 up to 1.6ms
- 通信:17–155us(主),偶发 up to 1.6ms
- 单微批总发量 / 每 GPU:~0.88MB;对等 ~7KB/peer/轮(EP=128)
- 重配置预算:≤50us(建议 10–30us)
数据计算方法
prefill:
- hidden_dim:默认 7168(从 kernel 维度可见 7168/16384/24576 等);范围 6k–12k。
- dtype_bytes:1–2(FP8/FP16/BF16,可选);默认 2(BF16/FP16)。
- bytes_total ≈ tokens_gpu_mb * hidden_dim * dtype_bytes
decode:
同上,将 tokens_gpu_mb 取代为请求数即可;N 请求 = N token。
把这些数据翻译成更有意义的结论
上面的内容更像“报告体”分析,如果换成更面向工程和建模的语言,可以把它压缩成三条主结论。
Prefill 和 Decode 不能共用同一种抽象
如果一个控制器只用一套统一参数去描述 Prefill 和 Decode,那么它大概率会丢掉最重要的信息:
- Prefill 偏大批量、高吞吐、长计算核、长尾通信
- Decode 偏小步长、高频、低时延、短通信
这就是为什么在建模时,至少应该把它们拆成两个阶段,甚至两套参数。
prompt length 和 tokens / GPU 必须区分
真实系统里:
prompt length = 4K是单请求语义16K tokens / GPU是单 GPU 的总工作量语义
如果模型里只有一个参数同时承担这两个角色,就一定会出现语义冲突。
Decode 是否占用 SM 是关键差异
对 Decode 来说,一个非常关键的系统级事实是:
- all-to-all 发出后不继续占用 SM
这决定了它和 Prefill 在重叠方式上的本质不同,也直接影响:
- 时延分布
- 资源占用
- 下一步开始前的等待方式



