MOE 学习笔记
Mixture of Experts (MoE) 是一种基于多个“专家”子模型(或专家网络)的架构,它通过路由策略(通常是基于输入数据的特征)动态选择一个或多个专家进行计算。
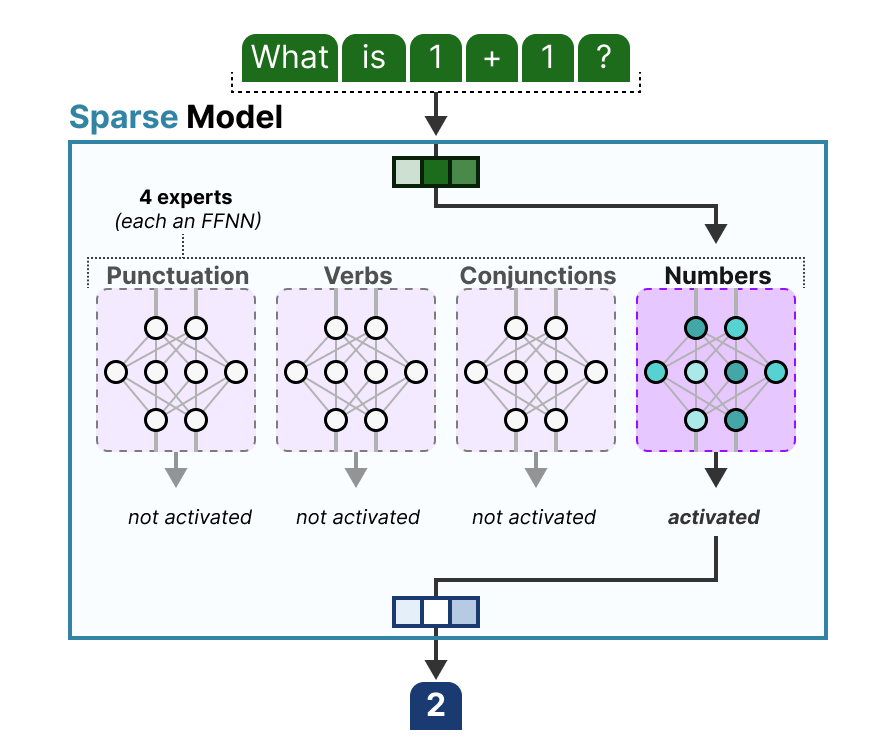
MOE是什么?
核心概念:
专家网络(Expert Network):每个专家网络通常是一个子模型(例如一个神经网络层),它们负责处理不同类型的任务或数据特征。
路由器(Router):路由器根据输入数据的特征来决定将其路由到哪个专家。通常,路由器会通过对输入的编码进行决策,选择一个或多个最适合的专家。
稀疏激活(Sparse Activation):不是所有的专家都会同时激活,通常每个样本只激活一部分专家,这样可以大大减少计算量,使得 MoE 可以在不增加计算成本的情况下使用更多的专家。
MOE 的主要优势
- 计算效率:MoE 允许模型在不显著增加计算开销的情况下增加专家数量。通过稀疏激活,模型只计算必要的部分。
- 灵活性:MoE 可以灵活地为不同任务选择不同的专家,适应更复杂的任务。
路由原理
MoE 模型的路由机制决定了输入数据如何分配给专家。路由的核心目的是通过选择最合适的专家来提高计算效率和模型性能。
常见的路由机制:
- 硬路由(Hard Routing):每个输入数据只被一个专家处理,路由器将输入直接分配给一个专家。
- 软路由(Soft Routing):每个输入数据被多个专家处理,但它们的激活度不同。通常,使用概率分配的方式,将任务按权重分配给多个专家。
实现方式:
- Top-k 路由:输入数据会被分配给 k 个最合适的专家。例如,选择 2 个专家来处理某个输入,其他专家不参与计算。
- 学习路由(Learned Routing):路由器本身是一个神经网络,负责根据输入的特征学习出最合适的专家选择策略。
路由机制的优势
- 灵活性与精确性:通过学习不同的路由策略,MoE 可以针对特定输入选择最有用的专家,从而提高性能。
模型结构
MoE 模型的结构由多个部分组成,主要包括 专家网络、路由器 和 聚合模块:
- 专家网络(Experts):这些是可以独立训练的小模型(例如深度神经网络)。每个专家通常是一个简单的前向神经网络,专注于某些特定的输入模式或任务。
- 路由器(Router):路由器用于决定哪些专家应该处理每个输入。它可以基于输入特征进行训练,并预测最合适的专家。
- 聚合模块(Aggregator):负责将多个专家的输出合并,生成最终的输出。对于 软路由,聚合模块通常通过加权平均或加和来实现。
典型模型结构
- 输入层:接收原始数据。
- 路由器:决定输入应该由哪个或哪些专家处理。
- 多个专家:根据路由器的决定,多个专家分别处理输入数据的不同部分。
- 聚合层:将各个专家的输出汇总。
- 输出层:生成最终的模型预测。
均衡负载
均衡负载是 MoE 中的一个重要概念,旨在确保所有专家的计算负载尽量均衡。
问题:
- 如果某些专家过于频繁地被激活而其他专家几乎没有被使用,可能会导致一些专家的计算资源浪费,而另一些则超负荷工作。
解决策略:
- 专家容量控制:限制每个专家的最大处理能力,避免过度负荷。
- 负载均衡算法:设计一种策略,使得路由器能够更均匀地将任务分配给各个专家,避免出现某些专家被频繁激活而其他专家几乎未被使用的情况。
常见策略:
- 动态负载均衡:根据每个专家的负载情况动态调整路由策略,使得每个专家的计算量尽可能接近。
- 加权路由:路由器可以根据每个专家当前的负载情况分配任务,避免某些专家过载。
专家选择
专家选择是 MoE 中的关键部分,直接影响模型的性能和计算效率。
选择原则:
- 选择最适合当前输入的专家:不同的输入可能需要不同类型的专家。路由器通过对输入进行特征提取,选择最适合处理该输入的专家。
- 选择多个专家:在某些情况下,多个专家可能会被同时激活,特别是在复杂任务中,每个专家可能只处理一部分问题,因此选择多个专家可以更好地解决问题。
策略:
- Top-k 策略:为每个输入选择 k 个最相关的专家进行计算。通常,选择的专家数目不会很多,以保持计算效率。
- 流量控制:确保任务均匀分布,避免单个专家被过度激活而导致性能下降。
专家容量
专家容量是指每个专家可以处理的最大输入量。合理的容量控制对于 MoE 模型的训练与推理至关重要。
容量控制的意义:
- 防止专家饱和:每个专家的计算能力有限,超载可能导致计算资源的浪费或性能下降。
- 提高计算效率:通过合理控制每个专家的处理量,可以避免一些专家过载,而其他专家闲置,确保模型资源的高效使用。
常见方法:
- 容量限制:限制每个专家同时处理的样本数,以避免某些专家过度饱和。
- 专家动态调整:根据专家的负载动态调整其可处理的输入量,确保负载均衡。
推理(inference)
Mixture of Experts (MoE) 模型的推理流程与传统的全连接神经网络不同,因为它通过路由机制动态选择专家来处理输入数据,从而使得计算更加高效。下面我将详细讲解 MoE 推理的具体流程,包括每个步骤的技术细节、关键组件和推理过程中如何选择专家以及如何处理输出。
MoE 推理流程概述
- 输入数据预处理
- 路由机制
- 专家选择与执行
- 输出聚合
- 结果后处理
输入数据预处理
推理过程的第一步是对输入数据的预处理。这一步骤通常包括以下内容:
- 标准化与归一化:输入数据会被标准化或归一化到适当的范围,这对神经网络模型来说是一个常见的步骤。
- 向量化:将输入数据转换为适合模型处理的向量表示。这些向量表示通常是嵌入层或其他预处理层的输出。
输入预处理示例
如果你的任务是处理文本数据,输入可能是一个词序列,经过嵌入层后,输入将被转化为一个高维向量,作为后续推理的基础。
路由机制
路由是 MoE 推理中的核心部分,决定了输入数据将被送往哪些专家进行处理。在这一阶段:
- 路由器(Router):路由器是一个独立的神经网络模块,负责根据输入特征决定哪些专家应该处理该输入。它通常是一个轻量级的网络,通过对输入的特征进行处理,预测出最适合的专家。
- 路由策略:常见的路由策略有 硬路由(hard routing) 和 软路由(soft routing)。
- 硬路由:每次输入会被送往一个或多个特定的专家。每个输入只有一个或几个专家被激活,其他专家则不参与计算。
- 软路由:输入被分配给多个专家,每个专家的激活权重会有差异。这种方式通常使用概率分布来决定每个专家的激活程度。
路由步骤:
- 输入数据通过路由器网络,得到一个分配向量(例如,Softmax 函数输出的概率分布)。
- 根据路由器的决定,选择 Top-k 个最适合的专家进行处理。
路由机制示例
假设 MoE 模型有 64 个专家,输入经过路由器后,路由器选择了 Top-2 个最合适的专家进行处理。这样,模型只会激活这两个专家,而其他 62 个专家将保持不激活状态。
专家选择与执行
一旦路由器决定了哪些专家负责处理输入数据,下一步是专家的计算过程。
- 专家网络(Experts):每个专家通常是一个深度神经网络,可以是一个独立的前馈网络或包含多个层的复杂网络。每个专家专注于处理特定类型的输入数据。
- 稀疏激活(Sparse Activation):MoE 采用稀疏激活机制,只有少数几个专家被激活,而其他专家则不参与计算。这样,MoE 可以在相对较小的计算成本下使用大量专家。
- 并行处理:多个专家可以同时进行计算,这通常是通过数据并行化实现的。每个被选择的专家都会独立处理其分配到的输入,并产生输出。
专家执行示例
- 专家 1 负责处理输入数据中的一个模式(例如,处理某种特定的语义特征)。
- 专家 2 处理输入数据中的另一个模式(例如,处理另外一种特定的语义特征)。
在这个阶段,每个专家会对输入进行前向传播计算,并产生输出。
输出聚合
由于 MoE 模型在推理时可能激活多个专家,因此这些专家的输出需要被合并(或聚合)为最终结果。
- 聚合方式:
- 加权平均:当多个专家被激活时,它们的输出通常会按一定的权重进行加权平均。权重通常由路由器输出的概率值或其他机制决定。
- 加和(Sum):对于多个激活的专家,它们的输出也可以简单地加和。加和的方式常用于一些回归任务中。
- 聚合过程:聚合层将来自不同专家的输出组合在一起,以形成最终的模型预测。通常聚合是在最后一层进行的,使用加权平均或加和的方式。
输出聚合示例
假设路由器选择了专家 1 和专家 2 进行计算,专家 1 产生的输出是 [0.2, 0.4],专家 2 产生的输出是 [0.5, 0.3],路由器为这两个专家分配的权重分别是 0.7 和 0.3。那么聚合过程将是:
- 聚合结果 =
0.7 * [0.2, 0.4] + 0.3 * [0.5, 0.3] = [0.29, 0.37]
结果后处理
最后,聚合后的结果通常需要进行一些后处理步骤,以生成最终的输出。这些后处理步骤可能包括:
- 激活函数:对输出进行非线性变换,例如使用 Softmax 函数将输出转换为概率分布。
- 损失函数计算:在推理过程中,模型输出会与真实标签进行比较,并计算损失,这通常用于在线推理和训练阶段。
- 输出选择:根据任务的需要选择最终输出。例如,在分类任务中,通常选择概率最高的类别作为最终预测。
MoE 推理流程总结
- 输入数据预处理:将原始输入转化为适合处理的向量表示。
- 路由机制:路由器根据输入数据的特征选择适合的专家进行处理。
- 专家选择与执行:被选择的专家独立处理输入数据,生成输出。
- 输出聚合:将多个专家的输出根据权重进行加权平均或加和,得到最终输出。
- 结果后处理:进行必要的激活函数处理,得到最终的预测结果。
Prefill 和 Decode
Prefill 阶段
Prefill 阶段主要是 为后续的推理过程预处理数据,在一些大型语言模型推理过程中,这一阶段的主要任务是将输入文本进行处理并准备好相应的计算任务,以便后续的解码(Decode)阶段能够高效进行。
Prefill 的原理
- 任务:将输入的文本数据(如文本或 prompt)切分为 tokens,并将其映射到模型的嵌入空间。这一过程包括对输入数据的 预处理 和 数据准备。
- 输入数据:通常是一个 长序列 或 多批量请求(batch),并且可能通过 tokenization 来处理。例如,长文本会被分割成 4K tokens。
- 硬件使用:
- GPU:在 Prefill 阶段,GPU 负责执行 前向计算(如嵌入矩阵乘法),并将输入数据处理为适合进行后续计算的形式。
- 网络:如果是分布式推理,网络会在不同节点之间传递预处理后的数据,特别是在多个 GPU 之间进行通信,确保数据一致性和同步。
Prefill 与硬件协同
- GPU:主要处理输入数据的 嵌入计算(embedding)和 前向传播(forward pass)。通过充分利用 GPU 的并行计算能力,将大量 token 的处理加速。
- CPU:在某些情况下,CPU 可能会负责初步的数据预处理、tokenization 和分配工作,随后将数据传输到 GPU。
- 网络:如果是多机多卡的设置,网络会承担 数据的同步与传输,尤其是在 分布式训练 或 推理 环境下,预处理后的数据需要快速传递到每个 GPU。
Decode 阶段
Decode 阶段是 MoE 模型实际进行推理计算的核心部分。在这一阶段,模型会基于预处理的输入生成输出,通常是文本的生成或翻译任务中的预测词语。
Decode 的原理
- 任务:在 Decode 阶段,模型接收到从 Prefill 阶段得到的嵌入数据,并根据当前的上下文和输入,逐步预测下一个 token 或单词。对于生成式模型,Decode 也涉及到 autoregressive 的生成过程,即基于之前的输出继续生成新的内容。
- 硬件使用:
- GPU:主要用于 并行计算,加速每个 token 的生成过程。由于 MoE 是一个稀疏激活的模型,Decode 阶段会通过 路由器 动态地选择最合适的专家进行计算,这要求 GPU 高效地处理大规模的并行计算任务。
- CPU:CPU 在这一阶段的作用较小,主要用于调度和辅助管理一些低优先级的任务,如数据传输和模型的调度。
- 网络:在 分布式推理 场景下,Decode 阶段可能会有大量的 all-to-all 通信,特别是在 MoE 模型中,多个专家可能需要进行通信以完成某一 token 的计算。
Decode 与硬件协同
- GPU:GPU 负责高效地执行模型推理,特别是 MoE 的 专家路由(routing),每个专家负责不同的数据片段。GPU 提供了 大规模并行计算 的能力,可以在每个阶段对大量的 token 进行处理。
- 网络:由于 MoE 是分布式的,网络在 Decode 阶段尤为重要。特别是在解码过程中,所有 GPU 需要进行 频繁的 all-to-all 通信,以便不同的专家能够同步计算结果。
Prefill 和 Decode 的关系
这两个阶段紧密相关,Prefill 为 Decode 阶段提供了必需的数据结构和预处理数据。它们的协同工作确保了推理的顺利进行。
两个阶段的关系
- Prefill 阶段处理 原始输入,并生成 token 嵌入,这些嵌入将作为 Decode 阶段的输入。
- Decode 阶段利用 Prefill 提供的嵌入数据,基于上下文生成 后续 token,并根据需要在每次推理时动态选择不同的专家进行计算。
这种结构的协同优势在于:
- 输入预处理和模型计算的分离:通过预处理阶段减少了 Decode 阶段的计算压力。
- 硬件资源的高效利用:GPU 能够并行地处理大规模的 token,而网络确保在多节点多 GPU 环境中,数据能够高效地流动和同步。
- 动态调度和专家选择:在 Decode 阶段,MoE 的路由器会根据输入的上下文,动态选择最合适的专家进行处理。
硬件协同的详细机制
- GPU 与 CPU 协同:在大规模推理任务中,通常会有多个 GPU 协同工作,GPU 负责计算密集型任务(如前向传播和专家计算),而 CPU 负责管理任务调度、数据传输等较低优先级的任务。
- 网络带宽与通信协同:
- Prefill 阶段:如果是多机多卡设置,网络主要负责分配数据和同步工作,确保每个 GPU 都能接收到正确的输入。
- Decode 阶段:当 MoE 需要进行 all-to-all 通信时,网络带宽会成为瓶颈。为了确保推理的实时性,DeepSeek 通过优化网络通信策略(如减少不必要的通信、批量传输)来缓解这一问题。
网络行为
MoE 的网络行为和普通稠密模型最大的不同,在于它不是“层与层之间按固定拓扑同步一次”这么简单,而是会随着 路由结果 动态变化。
当输入 token 被路由到不同专家之后,系统需要把这些 token 对应的中间表示发送到目标专家所在的计算节点,再把专家输出聚合回来。因此,MoE 的网络行为本质上是由 路由、专家分布、批量大小、激活专家数 TopK 共同决定的动态多对多通信。
通信路径的基本结构
从一次典型的 MoE 层前向过程来看,网络行为通常可以抽象成下面几个步骤:
- 路由器根据输入 token 的特征,为每个 token 选出若干个目标专家。
- 系统根据专家所在的位置,把 token 对应的激活、隐藏状态或中间表示发送到对应专家。
- 各专家在本地完成前向计算。
- 专家输出再被发送回原先的聚合位置,或发送到下一层所需的位置。
在工程实现里,这两次通信常被称为:
- Dispatch:把 token 分发给目标专家。
- Combine:把专家计算结果聚合回来。
如果专家分布在多个 GPU 或多个节点上,这两个阶段都会体现为明显的网络流量;如果专家刚好落在同一个设备内部,则更多体现为本地显存搬运或片上同步。
MoE 网络行为的几个核心特征
多对多
MoE 通常不是一对一或一对多,而是典型的 many-to-many 通信。
一个 GPU 上的一批 token 可能被路由到多个专家,而这些专家又可能分布在多个不同 GPU 上;与此同时,其他 GPU 上的 token 也会路由到本 GPU 承载的专家。因此,从网络视角看,MoE 更接近一种稀疏的 all-to-all。
流量受路由影响
MoE 的通信量并不是固定的,它会受以下因素影响:
- TopK:每个 token 激活几个专家。TopK 越大,分发目标越多,通信规模通常越大。
- 批量大小:同一轮参与路由的 token 越多,总体通信量越大。
- 专家负载均衡程度:如果路由不均衡,部分专家会收到更多 token,对应链路也更容易形成热点。
- 专家布局:如果专家更多地落在本地 GPU 内,跨节点通信会减少;如果专家跨节点分布更分散,RDMA 流量会更重。
突发性和长尾
MoE 的网络流量常常不是平滑连续的,而是 阶段性突发 的。
原因在于大量 token 会在路由决策后进入集中分发,再在专家计算完成后进入集中回传,因此很容易出现:
- 某一时刻短时间内流量陡增
- 一批主流 token 很快完成,但少数慢专家形成尾部等待
- 总体带宽利用率不低,但端到端时延被长尾拖住
这也是为什么在真实系统里,MoE 不仅要看平均带宽,还要看 tail latency、负载均衡和通信-计算重叠程度。
Prefill 阶段的网络行为
Prefill 阶段的特点是:单轮工作量大、单轮消息大、通信与计算重叠更明显。
其原因主要有三点:
- 输入 prompt 在 Prefill 时是整段进入模型的,参与计算的 token 总量大。
- 每一层都会产生需要路由的中间表示,因此单轮 dispatch/combine 的数据体积更大。
- Prefill 往往会和较长的 Attention、GEMM 等计算核交错执行,所以更容易形成“边算边发”的重叠行为。
从网络上看,Prefill 更像是:
- 低频但大包
- 总流量大
- 单轮 all-to-all 持续时间更长
- 更容易出现毫秒级尾部通信
如果是多 micro-batch 设计,系统还会尝试让一个 micro-batch 在计算时,另一个 micro-batch 正在进行通信,以提高整体资源利用率。
Decode 阶段的网络行为
Decode 阶段的特点则几乎相反:单步工作量小、消息更短、频率更高、对时延更敏感。
因为 Decode 通常是逐 token 推进的,每一步只为当前生成位置进行一次前向计算,所以:
- 每一步参与路由的数据量较小
- 单次 dispatch/combine 的消息更小
- 但由于生成过程会反复执行,通信发生得更频繁
从网络上看,Decode 更像是:
- 高频但小包
- 平均带宽未必最高
- 但每一步的通信延迟直接影响 token 生成延迟
- 对同步等待和尾部抖动更敏感
在 DeepSeek 这类优化实现里,Decode 阶段的一个关键点是:all-to-all 通过 RDMA 发出后,不继续占用 SM。
这意味着 Decode 的通信虽然频繁,但可以更充分地和后续计算重叠;真正影响单步延迟的,往往是计算结束后还未完成的那一小段尾部等待。
网络行为为什么会成为 MoE 的瓶颈
在稠密模型里,增加 GPU 往往主要解决计算量问题;但在 MoE 里,随着专家数、节点数和并行规模上升,网络可能比计算更早成为瓶颈。常见原因包括:
- 跨节点 all-to-all 过于频繁
- 热点专家导致链路负载不均
- 消息粒度过小,协议与软件栈开销占比变大
- 通信与计算重叠不足,导致纯等待时间上升
因此,真实系统在设计时通常会围绕以下目标优化:
- 尽量减少不必要的跨节点流量
- 提高专家负载均衡性
- 让 dispatch/combine 与计算阶段尽量重叠
- 针对 Prefill 和 Decode 分别采用不同的通信内核和调度策略
理解网络行为时可以抓住的主线
如果只是把这一部分当作学习笔记来理解,可以抓住下面这条主线:
- 路由决定流向:token 会被送往哪些专家,首先由路由器决定。
- 专家分布决定路径:专家如果跨 GPU、跨节点分布,通信路径就会更长、更复杂。
- 批量大小决定总流量:一轮里 token 越多,需要分发和聚合的数据就越多。
- TopK 决定通信扩散程度:每个 token 激活的专家越多,分发目标通常也越多。
- 阶段决定节奏:Prefill 更偏大包、长时段重叠;Decode 更偏小包、高频、低时延。
也就是说,MoE 的网络行为并不是一个静态带宽问题,而是一个由 模型结构 + 路由决策 + 批量组织方式 + 执行阶段 共同决定的动态过程。
小结
MoE 的网络行为可以概括成一句话:
路由决定流向,专家分布决定路径,批量大小决定流量规模,Prefill 和 Decode 决定通信节奏。
如果要继续深入,可以重点关注三件事:
- TopK 和专家布局如何影响 all-to-all 规模
- Prefill 与 Decode 为什么需要不同的网络抽象
- 通信与计算的重叠程度为什么会直接影响端到端推理效率




